




High-Availability & Clustering
Our HA Clustering solutions provide maximum up-time for your critical systems even in hardware / software / network failures
Clusters fall into four major types:
Storage
provide a consistent file system image across servers in a cluster, allowing the servers to simultaneously read and write to a single shared file system.
High Availability
eliminate single points of failure and by failing over services from one cluster node to another in case a node goes becomes inoperative.

Load Balancing
dispatch network service requests to multiple cluster nodes to balance the request load among the cluster nodes.

High Performance
carry out parallel or concurrent processing, thus helping to improve performance of applications.

Linux HA Cluster
Solution
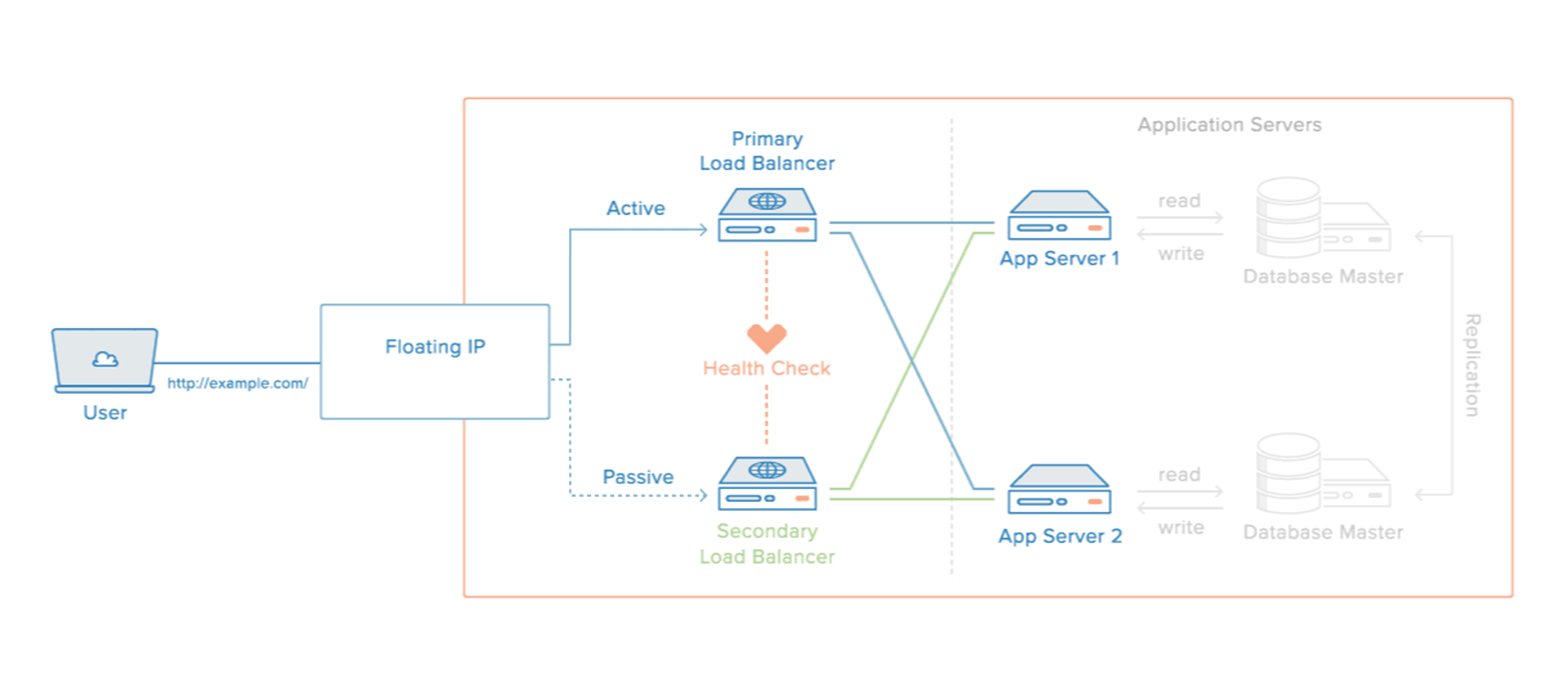
We provide Pacemaker, Corosync and DRBD/GFS2/SAN based high-availability cluster solutions to organizations around the world, for running critical systems without down-times. The cluster automatically failover services, data and databases from one cluster node to another in case a node become inoperative.
Our HA clusters consists of:
- Active-Active Node based clusters
- Active-Passive Node based clusters

Storage Cluster
Solution
Our storage cluster solution are based on Gluster and Ceph. Using common off-the-shelf hardware, you can create large, distributed storage solutions for media streaming, data analysis, and other data- and bandwidth-intensive tasks.

High-Available
Database Solutions
- SQL Server database mirroring solutions
- SQL Server always-on high availability groups
- SQL Server replication and log shipping solutions
- Oracle Data Guard implementation
- Oracle real application cluster solutions
- MySQL clustering solutions
- PostgreSQL clustering solutions
CONTACT US FOR HIGH-AVAILABILITY & CLUSTERING SOLUTIONS
